Vamos a ver en el post de hoy como HPE VM Essentials dispone nativamente de un mecanismo de alta disponibilidad o HA para poder dar alta resilencia a nuestros servicios en caso de una falla hardware en alguno de los nodos.
VER TODA LA SERIE DE POSTS
- Parte 1 - Introducción a HPE Morpheus VM Essentials software
- Parte 2 - Instalación VM Essentials software
- Parte 3 - Instalación VME Manager
- Parte 4 - Configuración inicial
- Parte 5 - Creación cluster Ceph
- Parte 6 - Desplegar nuestra primera VM
- Parte 7 - Backups nativos
- Parte 8 - Pruebas de HA
- Parte 9 - Migración de VMs desde vSphere
- [Parte 10 - Comandos útiles]
- Parte 11 - Gestión de actualizaciones en HPE VM Essentials
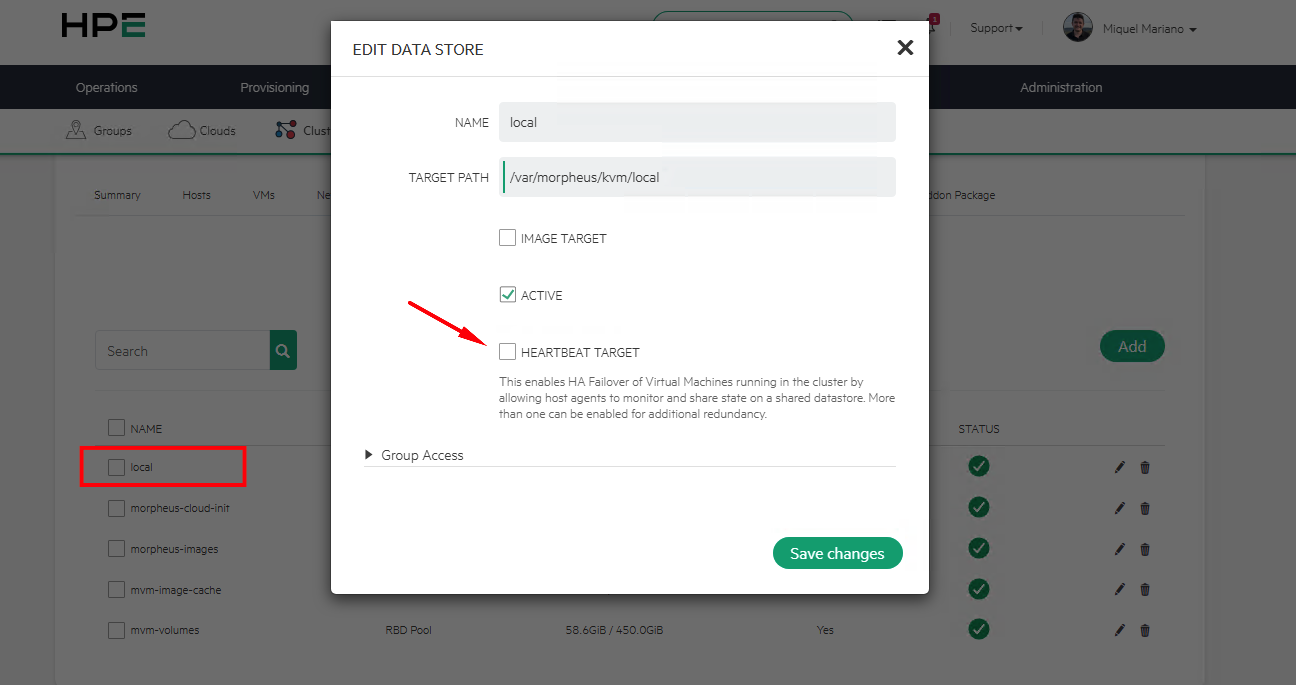
Antes de nada, para que el mecanismo de HA funcione, es necesario habilitar heartbeat en nuestros datastores a nivel de clúster. De esta manera, todos los miembros del cluster se “comunican” a través de este datastore para determinar si estan o no OK
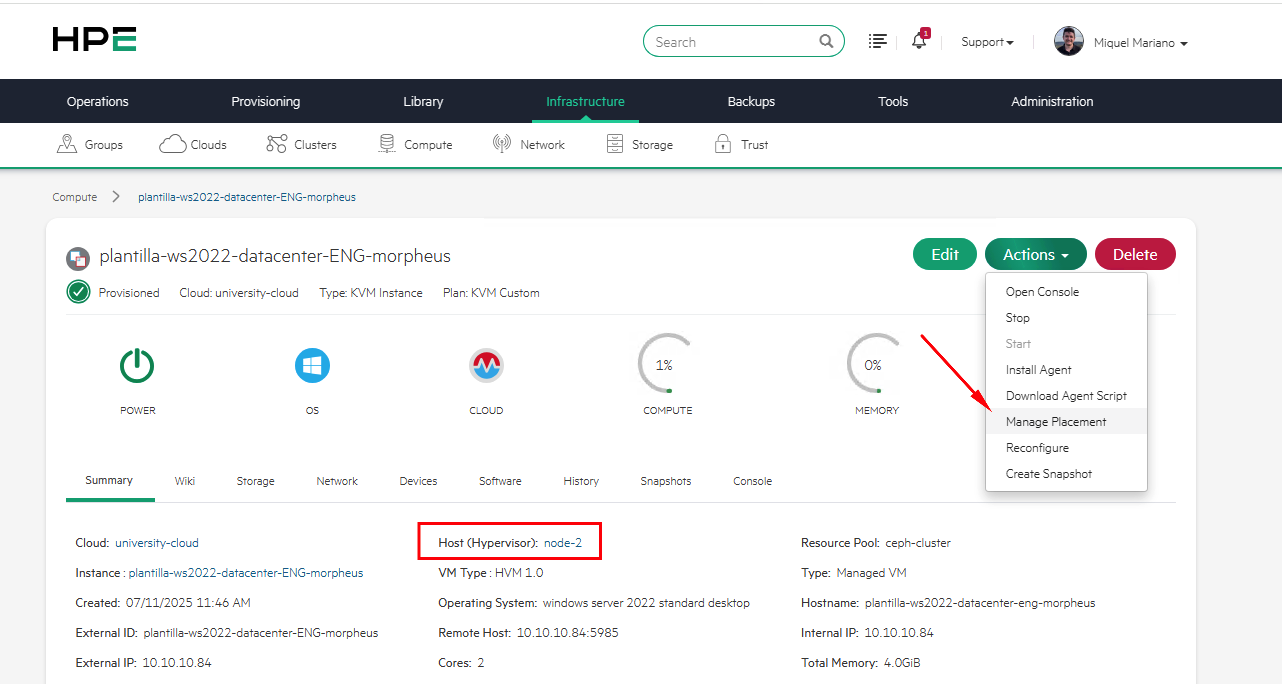
Arrancamos las pruebas validando inicialmente en que nodo tenemos nuestra VM. Recordar que para mover VMs entre los diferentes nodos usaremos la acción de “Manage Placement”
En mi caso, tenemos la VM corriendo sobre el nodo-2
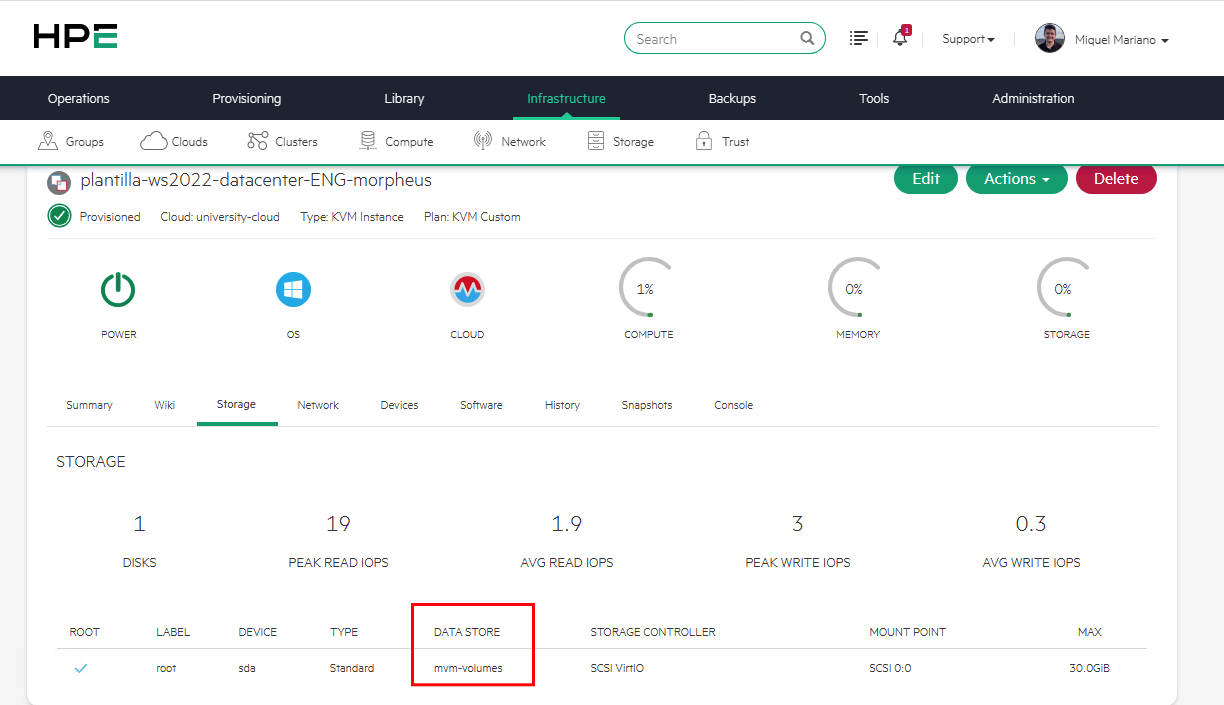
También es necesario que la VM esté alojada en un repositorio compartido. En nuestro caso, está sobre un Datastore CEPH
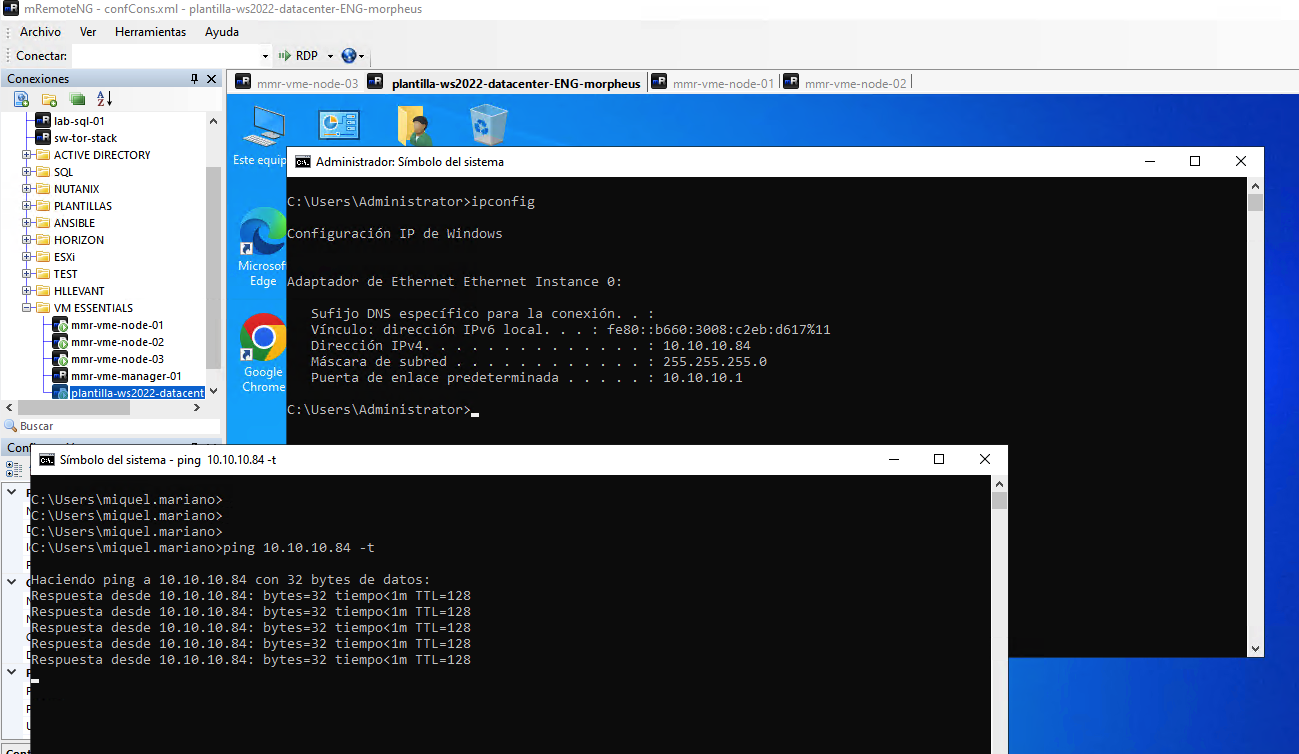
Validamos que la VM está encendida, está accesible y contesta a ping.
Como el nodo-2 en realidad es una VM vSphere, nos conectamos al vCenter y apagamos directamente la VM
La VM se cae y deja de responder
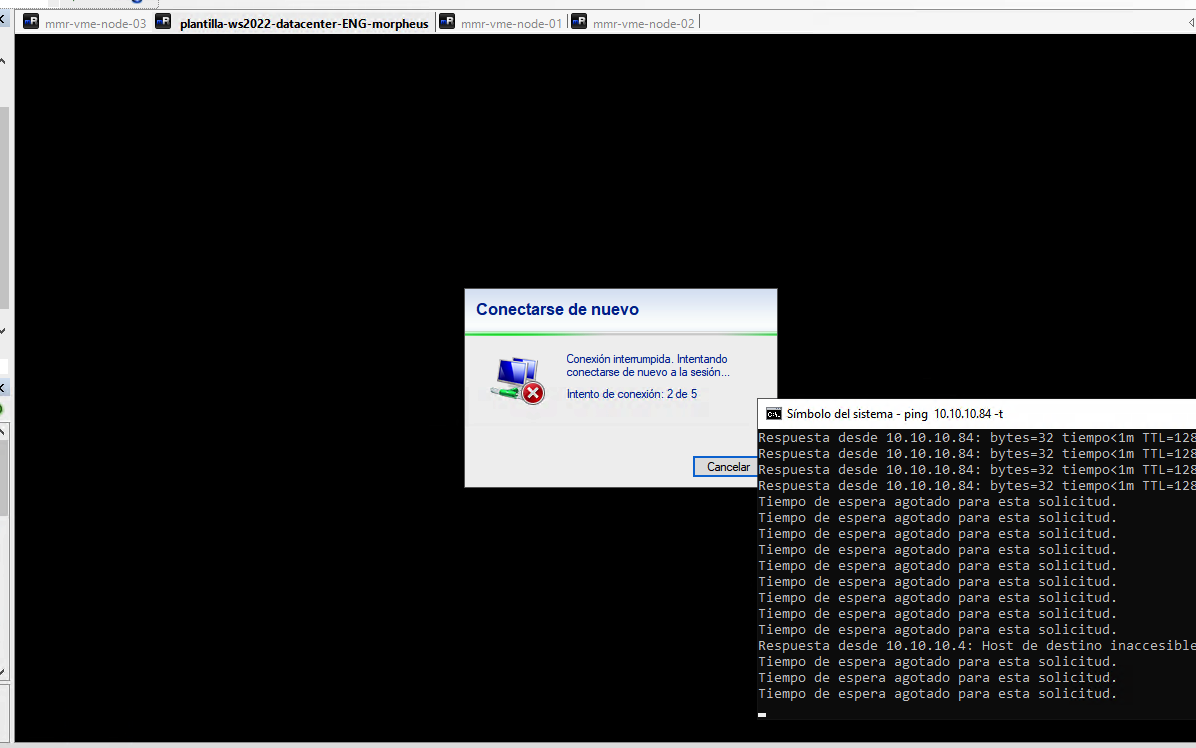
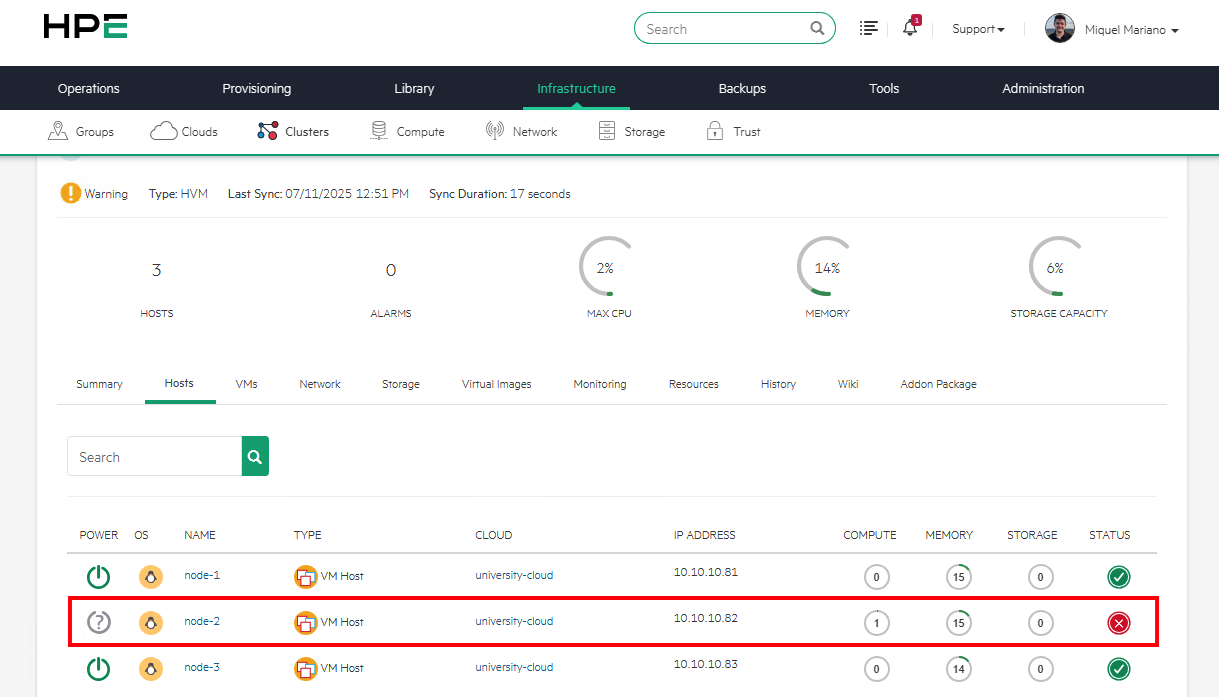
El cluster detecta la caída
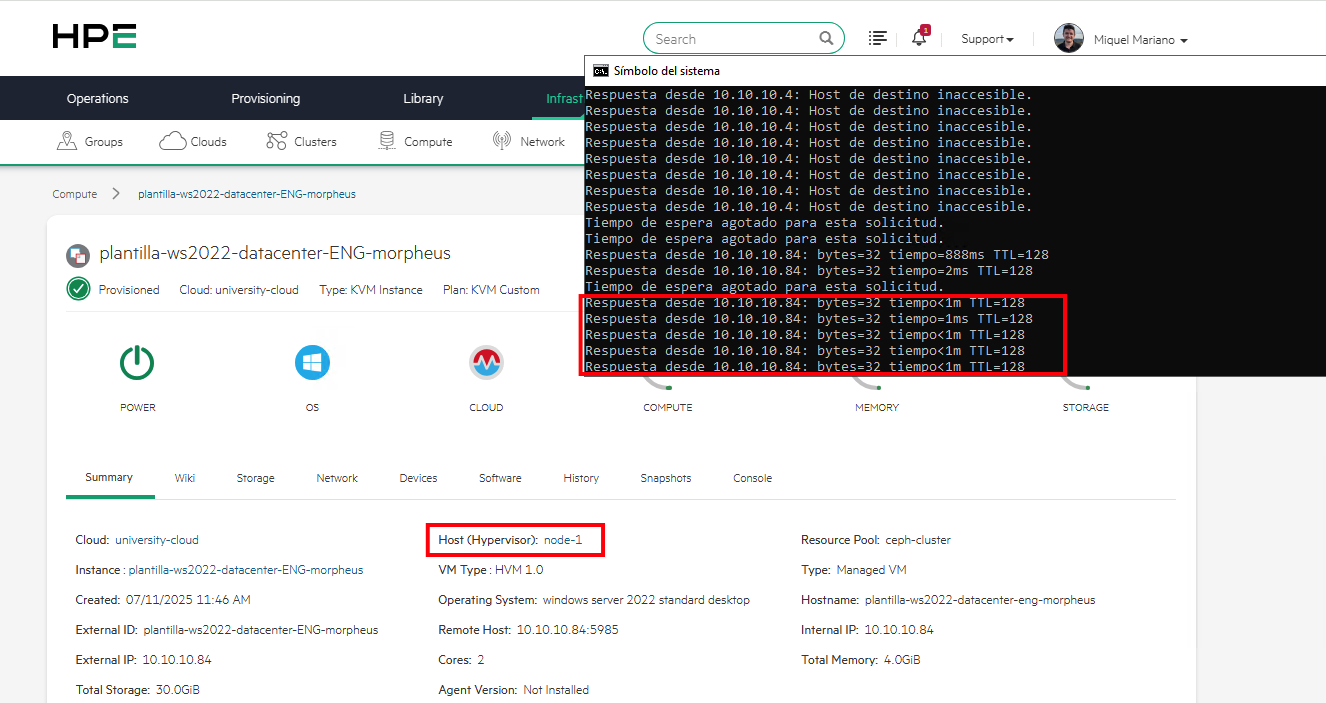
Finalmente, vemos como automáticamente la VM arranca en otro nodo del cluster y nos vuelve a contestar a ping
Nos vemos en el próximo post ;-)
Un saludo
Miquel.