
Buenos días a tod@dos, queridos lectores del blog.
Hoy quiero recuperar un post que publiqué en #ElBlogDeNcora, en el que hablábamos sobre una de las muchas tecnologías de replicación que tiene Hitachi Vantara.
Con la llegada de las cabinas enterprise VSP G1000/1500 y posteriormente la familia midrange VSP Gx00, llegó una nueva tecnología llamada GAD (Global Active Device), pero..
¿Que es GAD?
GAD o Global Active Device es una tecnología de replicación innovadora que viene a cubrir las necesidades de aquellos entornos en los que la perdida de servicio no es una opción. Esos entornos, los cuales están ligados a fuertes niveles de disponibilidad y que las arquitecturas activo-activo tanto a nivel de computo como de storage son indispensables.
De esta manera, GAD permite a los clientes una configuración de almacenamiento distribuido, tolerante a fallos y totalmente activo-activo sin ningún tipo de hardware externo (excepto el quórum, que veremos mas adelante)
Todo esto, a día de hoy, creo que ningún otro fabricante ha conseguido lograr
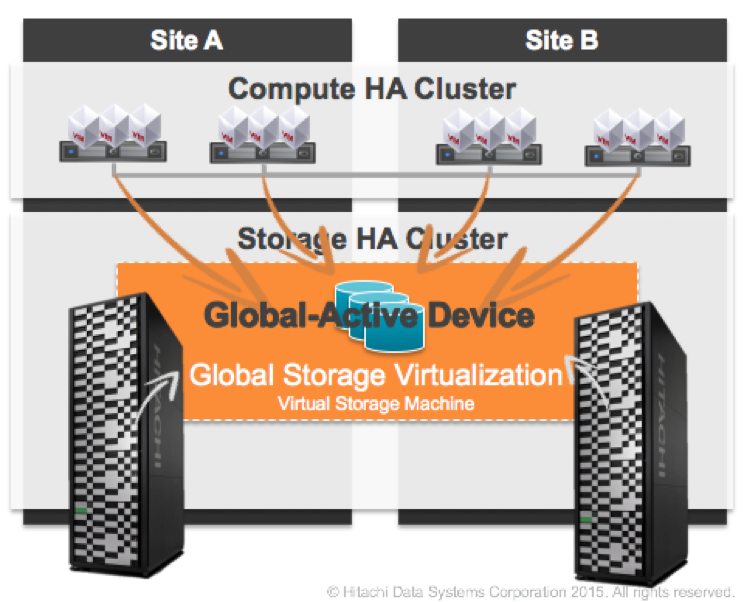
¿Cómo funciona GAD?
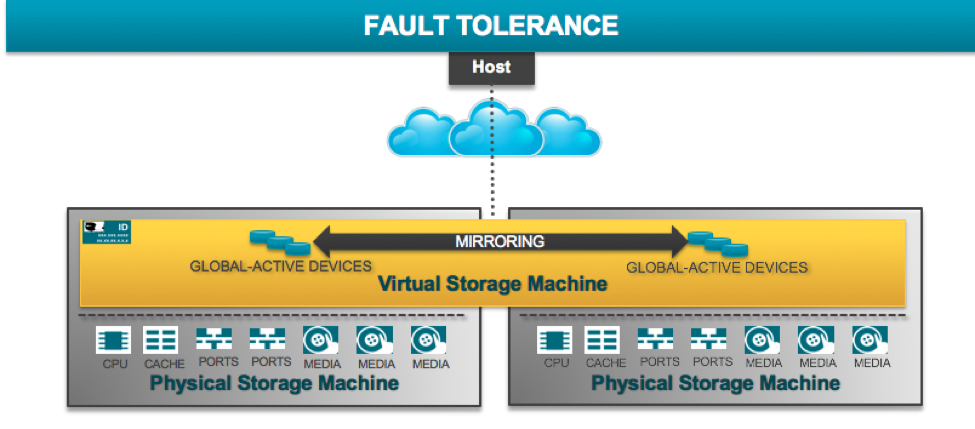
Como comentaba al principio, la llegada de las VSP G1000/1500 y posteriormente las VSP Gx00 fue totalmente revolucionario, ya que con ellas llegó un nuevo microcódigo, llamado SVOS (Hitachi Storage Virtualization Operating System). Y aquí en este cúmulo de acrónimos, la palabra mágica es Virtualization, si, con esta tecnología podemos virtualizar cabinas físicas y será la base sobre la que se sustenta GAD.
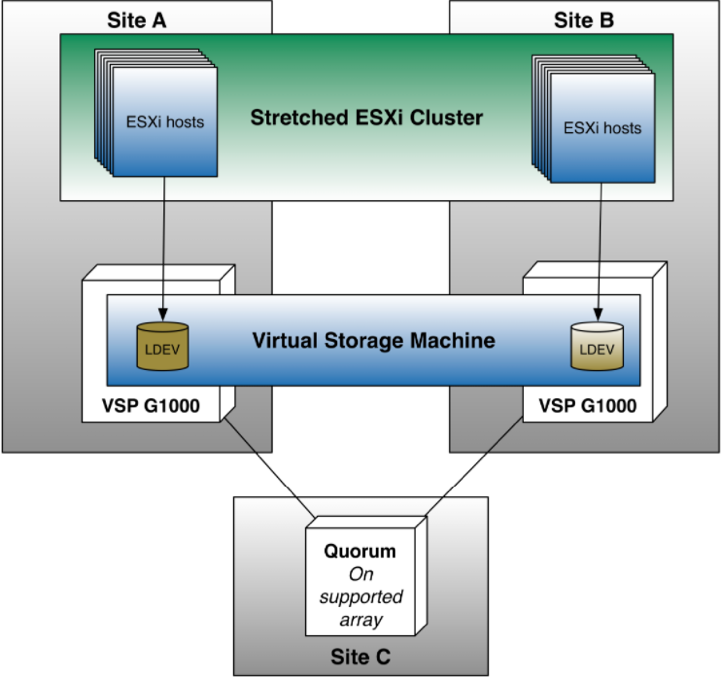
Con la virtualización de cabinas, aparece el concepto de VSM (Virtual Storage Machine) el cual consiste en añadir una capa por encima de las cabinas físicas con el objetivo de “hacer creer” a los hosts que solo disponemos de un sistema de almacenamiento.
En la representación inferior se ve como tenemos dos cabinas físicas, pero que por encima tenemos un objeto (VSM) con S/N 123456 que lo que hace es presentar el almacenamiento a los hosts como una única entidad.
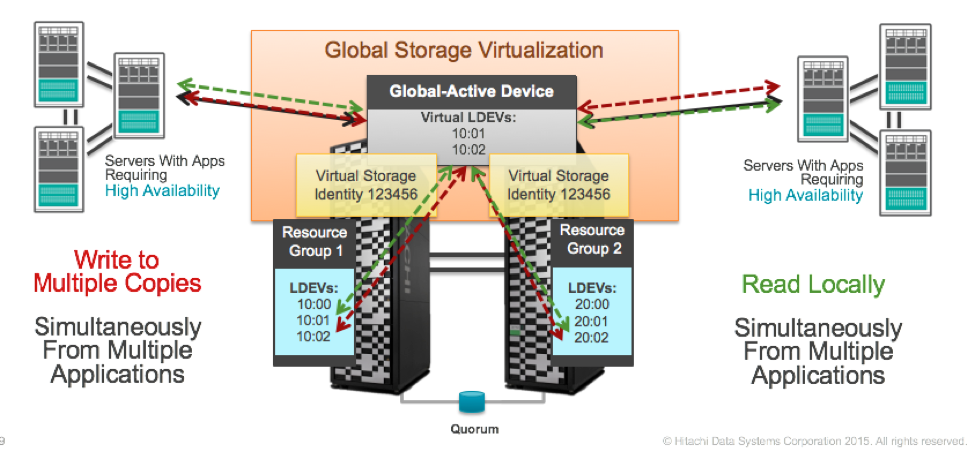
Llegados a este punto, los hosts son capaces de ver un único (o varios) volumenes de datos que realmente están distribuidos entre 2 sites y que son accesibles a través de múltiples paths. La pérdida o caída de uno de los sites, de cara al host, sólo implica la pérdida de la mitad de los caminos o paths. De ahí, la esencia de la tecnología activo-activo.
Bien, eso está muy bien, pero, ¿como consigo tener el dato redundado y consistente en dos sistemas físicamente autónomos?
Dejando de lado la capa de virtualización y la Virtual Storage Machine, y bajando otro nivel mas, GAD utiliza tecnología de replicación síncrona. Eso significa que los servidores que escriban un dato en una Virtual Storage Machine no recibirán el ACK de sistema de almacenamiento hasta que no esté guardado en ambos sistemas. Todo esto está controlado (como en la mayoría de sistemas en clúster) por un disco de quorum. Este Quorum tiene como requisito que tiene que pertenecer a un 3er sistema de almacenamiento (es lógico, ya que no se puede caer con la pérdida de una de las cabinas) y si es posible que está ubicado físicamente en un 3er CPD y así protegernos de una contingencia grave en el DataCenter.
Evidentemente el proceso está muy optimizado y solo replica las I/O de escritura, las I/O de lectura se leen sobre el sistema local.
Con esta tecnología de replicación conseguimos un RPO = 0 ya que el dato está asegurado en ambos site y un RTO muy cercano a 0 en caso de un entorno vSphere en el que HA tenga que reiniciar VM o incluso RTO = 0 si la parte de cómputo no se ha visto afectada y la caída solo a afectado al almacenamiento.

Gestión de multipathing
Como comentábamos en el punto anterior, cuando trabajamos con una Virtual Storage Machine y GAD “ocultamos” la información de los sistemas físicos y le host solo ve un único volumen distribuido por el cual puede acceder por diferentes caminos o paths.
Estos paths cobran vital importancia ya que, estaréis de acuerdo conmigo que un servidor que está en un SiteA, lo logico es que sus IOPS recaigan sobre la cabina que está en su mismo Site, que no tener que irse al site remoto.
Como sabéis, la mayoría de software nativo de multipathing tiene una política de RoudRobin, la cual balancea las I/O entre todos los caminos disponibles. Esto en realidad está muy bien, pero en el fondo no es lo mas óptimo cuando trabajamos con “paths locales” y “paths remotos” ya que nos interesa limitar este tráfico para que no salga de nuestro site.
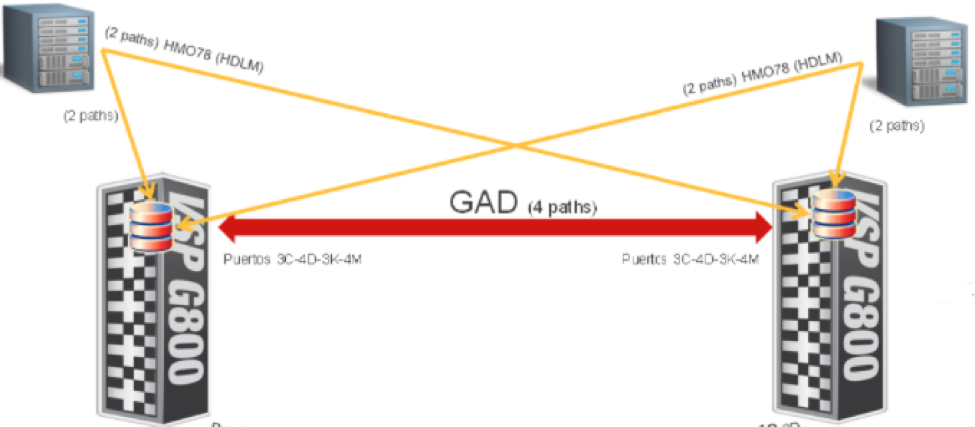
Para salvar este handicap, Hitachi tiene su propio software de gestión multipathing llamado HDLM (Hitachi Dinamic Link Manager) el cual, a partir de un sistema de flags, podemos “priorizar” el tráfico de almacenamiento por los caminos que creamos conveniente.
En el siguiente ejemplo, está representado un entorno con 2 sites replicados con GAD. Cada servidor ve 4 paths (2 locales + 2 remotos) y con el flag HMO78 le indicamos a los servidores que los caminos son remotos y que es mejor no mandar I/O por ahi. Evidentemente en caso de contingencia y que los paths locales no estuvieran disponibles, los I/O seguirían fluyendo por los paths remotos.
Casos de uso, vSphere Metro Storage
Ya para finalizar, en términos de arquitectura, la magia de todo es la creación de lo que se llama Virtual Storage Machine o VSM.
De esta manera, nuestros ESXi, miembros de un clúster vSphere, son capaces de ver datastores geográficamente distribuidos y con la suficiente tolerancia a fallos como para que la pérdida de un sistema de almacenamiento tenga 0 impacto sobre nuestra infraestructura y que la pérdida total de un CPD “sólo” tenga como consecuencia el downtime mínimo de lo que tarde el propio clúster HA en levantar las máquinas virtuales en el otro site.
Como siempre, espero que os sea de utilidad este post y si estáis interesados en profundizar más sobre esta tecnología o que os hagamos incluso una PoC, estaremos encantados de atenderos en comercial@ncora.com
Muchas gracias por leernos.
Un saludo!
Miquel